Appearance
Components of Kubernetes
Deploying containers and using Kubernetes may require a change in the development and the system administration approach to deploying applications. In a traditional environment, an application (such as a web server) would be a monolithic application placed on a dedicated server. As the web traffic increases, the application would be tuned, and perhaps moved to bigger and bigger hardware. After a couple of years, a lot of customization may have been done in order to meet the current web traffic needs.
Instead of using a large server, Kubernetes approaches the same issue by deploying a large number of small web servers, or microservices. The server and client sides of the application expect that there are one or more microservices, called replicas, available to respond to a request. It is also important that clients expect the server processes to be terminated and eventually to be replaced, leading to a transient server deployment. Instead of a large tightly-coupled Apache web server with several httpd daemons responding to page requests, there would be many nginx servers, each responding without knowledge of each other.
The transient nature of smaller services also allows for decoupling. Each aspect of the traditional application is replaced with a dedicated, but transient, microservice or agent. To join these agents, or their replacements together, we use services and API calls. A service ties traffic from one agent to another (for example, a frontend web server to a backend database) and handles new IP or other information, should either one die and be replaced.
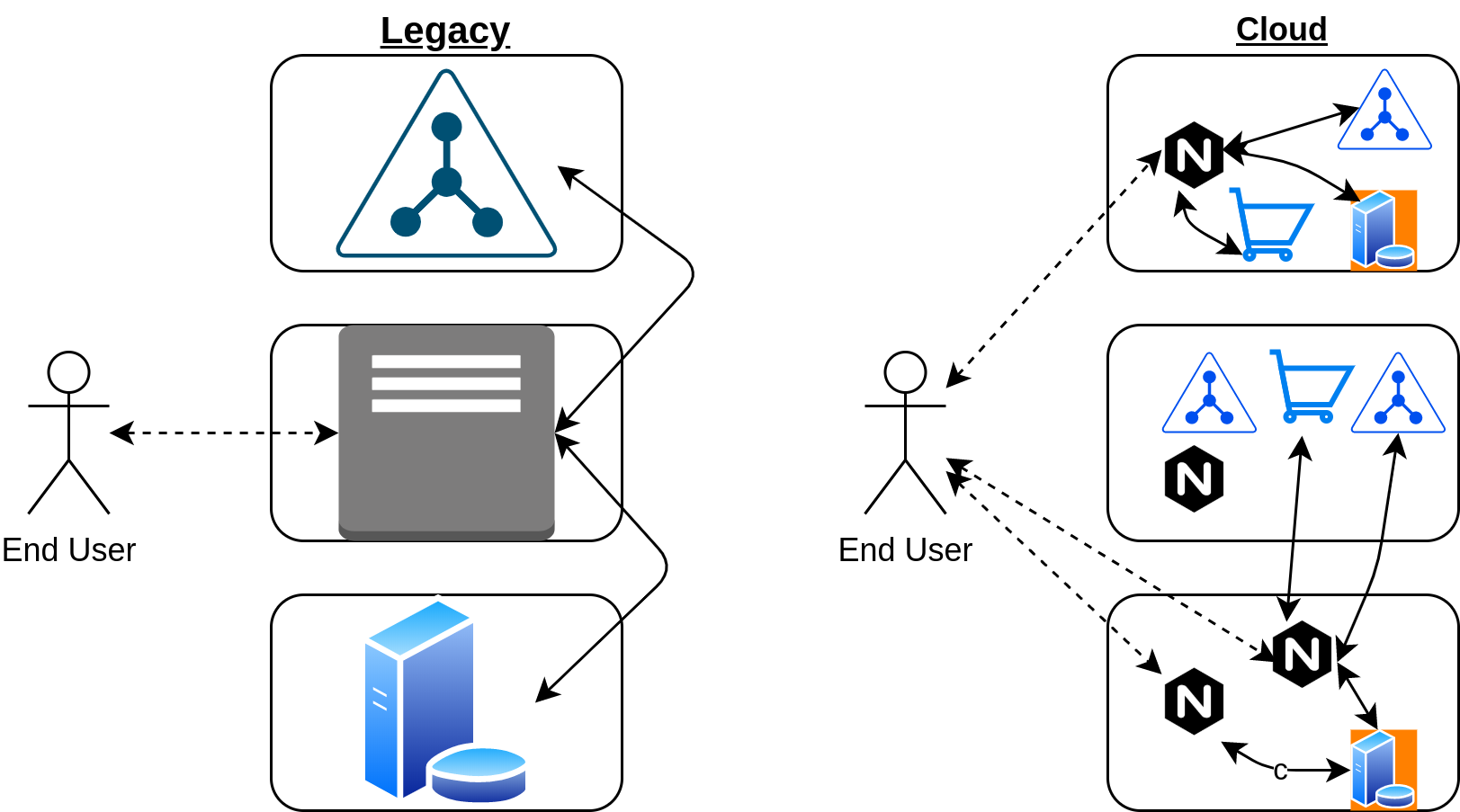
Developers new to Kubernetes sometimes assume it is another virtual-machine manager, similar to what they have been using for decades, and continue to develop applications in the same way as prior to using Kubernetes. This is a mistake. The decoupled, transient, microservice architecture is not the same. Most legacy applications will need to be rewritten to optimally run in a cloud. In the diagram below we see the legacy deployment strategy on the left with a monolithic applications deployed to nodes. On the right, we see an example of the same functionality, on the same hardware, using multiple microservices.
Communication to, as well as internally, between components, is API call-driven, which allows for flexibility. Configuration information is stored in a JSON format, but is most often written in YAML. Kubernetes agents convert the YAML to JSON prior to persistence to the database.